
A. 해싱
1. 해싱이란?
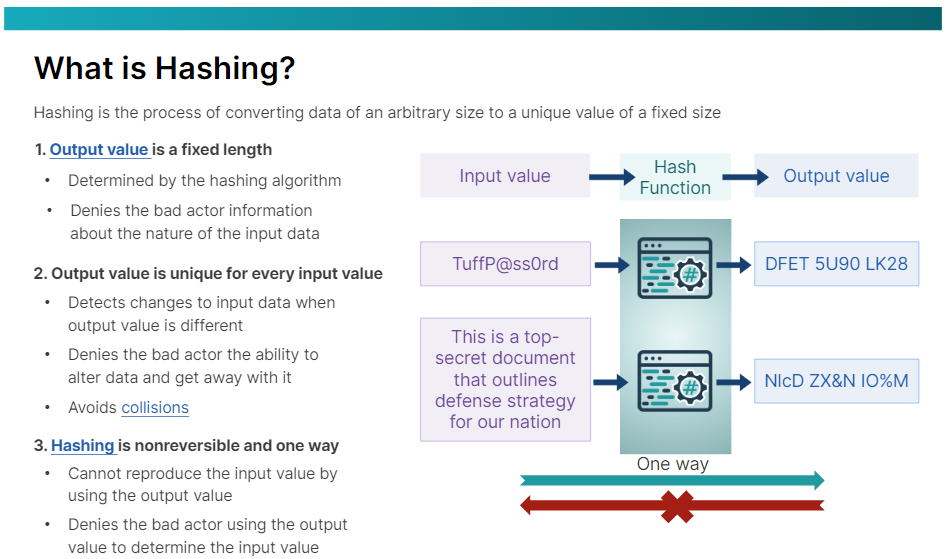
해싱은 임의의 크기의 데이터를 고정된 크기의 고유한 값으로 변환하는 프로세스입니다. 해싱에는 암호화를 지원하는 몇 가지 중요한 특징이 있습니다. 이러한 특징은 정의에서 언급됩니다.
첫째, 출력 값은 고정 길이이며, 해싱 함수나 알고리즘에 의해 결정됩니다. 출력 값은 주어진 알고리즘에 대해 항상 동일한 크기이기 때문에, 악의적인 행위자는 입력 데이터의 크기에 대한 지능이 없습니다. 12자리 비밀번호일 수도 있고 6페이지 문서일 수도 있습니다. 악의적인 행위자는 전혀 모릅니다.
두 번째, 충돌을 피하기 위해 출력 값은 모든 입력 값에 대해 고유합니다. 마치 지문이 모든 사람에게 고유한 것처럼요. 이 기능은 데이터 변경을 감지할 때 해싱을 매우 유용하게 만듭니다. 예를 들어, 누군가가 전자 문서를 변조한 경우, 비록 사소한 변경일지라도, 원본 문서의 해시 출력과 변경된 문서의 출력을 비교할 때 두 출력이 완전히 다르다는 것을 알게 되고 변조에 대한 경고를 받게 됩니다.
그리고 세 번째, 해싱은 되돌릴 수 없거나 단방향으로만 진행됩니다. 즉, 해싱 함수를 통해 출력 값을 실행하면 입력 값을 얻을 수 없습니다. 원래 출력 값의 출력 값을 얻게 됩니다. 이 기능은 악의적인 행위자가 출력 값을 사용하여 입력 값을 역엔지니어링하고 계산할 기회를 거부합니다.
2. 디지털 서명 생성 - 서명 과정
앞서 말한 해싱의 세 가지 보안 기능은 암호화에서 중요한 역할을 하며, 특히 디지털 서명을 생성할 때 중요합니다. 해싱의 보안 기능과 비대칭 암호화를 결합하면 디지털 서명을 생성할 수 있습니다. 디지털 서명은 여러 가지 목적을 위해 사용됩니다. 디지털 서명은 서명된 정보의 데이터 무결성을 보장하고, 정보에 서명한 사람이나 사물을 인증하며, 부인 방지를 지원합니다.
디지털 서명 프로세스의 첫 번째 단계에서는 서명해야 할 정보가 해시됩니다. 이렇게 하면 출력 해시 값이 생성됩니다.
두 번째 단계에서는 서명자와 연관된 비대칭 개인 서명 키는 비대칭 알고리즘을 사용하여 출력 값을 암호화합니다. 이 암호화된 출력 값을 디지털 서명이라고 합니다.
세 번째 단계에서는 디지털 서명이 정보에 첨부되며 서명된 정보를 확인하려면 해당 공개 확인 키가 필요합니다.

*Non-repudiation 부인 불가
누군가가 무언가의 유효성을 부인할 수 없다는 보장입니다. 데이터의 출처와 무결성에 대한 증거가 있기 때문에 서명자의 신원과 서명된 정보의 연관성 및 유효성에 대해 이의를 제기하기가 매우 어렵습니다.
예를 들어, 한 증권회사를 통해 A 씨가 "가" 주식을 샀다고 가정했을 때 이 주문은 A 씨가 서명하고 주문했다는 타임스태프가 찍힙니다. A 씨는 나중에 이 주문에 대해 이의를 제기하거나 부인할 수 없습니다. 주문이 A 씨에 의해 서명되었고 데이터의 무결성을 검증할 수 있기 때문입니다.
3. 디지털 서명 생성 - 인증 과정
키가 서명자의 소유라는 것을 어떻게 확인할 수 있을까요? 비대칭 암호화에서 공개 키는 인증서에 기록됩니다. 인증서는 인증 기관(CA)에서 발급하고 서명합니다. 공개 키 외에도 인증서에는 소유자 이름이 있습니다. 수신자는 저장소에서 검증 인증서를 검색하거나 서명된 문서에 첨부할 수 있습니다.
검증 과정의 첫 번째 단계에서는 수신자의 애플리케이션이 정보를 해시하여 새로운 출력 값을 생성합니다.
두 번째 단계에서는 서명자의 검증 인증서가 유효한지 확인한 후, 공개 키는 디지털 서명을 해독(즉, 검증)합니다.
세 번째 단계에서 검증자는 새 출력 값을 원래 출력 값과 비교합니다. 두 값이 같다면 정보가 변경되지 않았다는 것을 알 수 있습니다. 공개 키가 디지털 서명을 성공적으로 해독했고, 해당 키의 소유자 이름이 인증서에 기록되어 있으므로 서명자의 진위성을 확인할 수 있습니다.

4. 해싱 함수
MD5의 다섯 번째 버전은 128비트 해시 출력을 생성합니다. 이 기능은 주로 충돌에 대한 취약성이라는 약점이 발견될 때까지 널리 사용되었습니다. MD6는 MD5를 대체했습니다.
그 후, SHA-1이 더 인기를 얻었고, 그 뒤를 이어 SHA-2와 SHA-3가 뒤따랐습니다. SHA-1 함수는 160비트 해시 출력을 생성하는 반면, SHA-2는 실 제로 해싱 알고리즘 모음입니다. 이 모음에는 SHA-224, SHA-256, SHA-384, SHA-512가 포함됩니다. SHA-3을 사용하면 출력 값의 길이를 결정할 수 있습니다.
LANMAN은 레거시 Windows 운영 체제에서 비밀번호를 저장하는 데 사용되었습니다. LANMAN은 데이터 암호화 표준(DES)을 사용하는데, 이는 안전하지 않은 것으로 입증되었으며 무차별 대입 공격으로 무너질 수 있습니다. 해싱 및 디지털 서명 수업 NTLM은 LANMAN의 후속 버전이고, 그다음은 NTLM 버전 2입니다. HAVAL과 RIPEMD는 북미 외 지역에서 인기 있는 해싱 함수입니다.

5. 해싱 해독을 위한 일반적인 공격
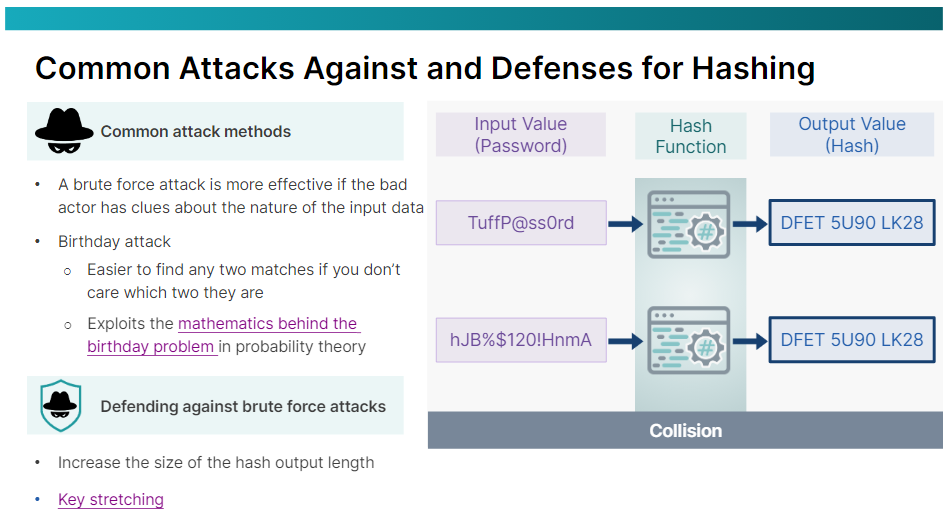
해싱을 해독하는 데 사용되는 매우 일반적인 방법은 무차별 대입 공격입니다. 즉, 악의적인 행위자는 원래 해시 출력과 동일한 값을 생성할 때까지 다양한 입력값을 시도하게 됩니다. 공격자가 입력데이터의 크기를 전혀 모른다면 무차별 대입 공격은 성공 가능성이 제한적입니다. 그러나 공격자가 입력 값에 대해 알고 있다면 적용되지 않는 입력 값을 제거할 수 있습니다.
예를 들어, 입력 값이 비밀번호이고 악의적인 공격자가 비밀번호 요구 사항을 알고 있는 경우(예: 최소 길이가 10자이고 최대 길이가 20자이며 대문 자, 소문자, 숫자를 포함해야 하지만 특수 문자는 포함하면 안 됨) 공격 범위를 크게 줄일 수 있습니다. 또 다른 예로, 악의적인 행위자가 해시 출력이 MD5를 사용하여 4자리 PIN을 보호하고 있다는 것을 알고 있다면 동일한 해시 출력에 도달할 때까지 상상할 수 있는 모든 조합을 시도할 수 있습니다.
무차별 대입 공격의 한 유형인 생일 공격은 생일 역설에 기반을 두고 있으며 충돌을 생성하는 것으로 알려진 해싱 함수를 악용합니다. 만약 당신이 183명의 사람과 함께 방에 있다면, 그중 한 명이 당신과 같은 생일을 가지고 있을 확률은 50%입니다. 하지만 만약 두 사람이 같은 생일을 공유할 확률을 50%로 하고 싶다면, 23명만 있으면 됩니다. 이것이 생일 역설입니다.

6. 해싱에 대한 일반적인 공격 및 방어
해싱 함수의 경우 이는 두 개의 일치 항목이 무엇인지 신경쓰지 않는다면 두 개의 일치 항목을 찾는 것이 훨씬 쉽다는 것을 의미합니다. 해시된 비밀번호를 해독하려고 시도할 때, 악의적인 행위자는 자신의 입력 데이터가 비밀번호와 일치하는지 신경 쓰지 않고, 입력 데이터가 동일한 해시 출력을 생성하는지에만 신경 씁니다.
이는 서버가 사용자 비밀번호를 저장하지 않기 때문입니다. 그들은 해당 비밀번호의 해시를 저장합니다. 따라서 나쁜 행위자가 앨리스의 비밀번호를 보호하는 해시 출력을 재생산할 수 있다면 앨리스로 로그인할 수 있습니다. 앞서 언급했듯이 두 개 이상의 입력 값이 동일한 출력 값을 생성하는 상황을 충돌이라고 합니다.
따라서 나쁜 행위자가 앨리스의 비밀번호를 보호하는 해시 출력을 재생산할 수 있다면 앨리스로 로그인할 수 있습니다. 앞서 언급했듯이 두 개 이상의 입력 값이 동일한 출력 값을 생성하는 상황을 충돌이라고 합니다. 생일 공격은 확률 이론에서 생일 문제의 수학을 활용합니다. 생일 공격의 성공은 주로 무작위 공격 시도와 고정된 순열의 정도 사이에서 충돌이 발견될 가능성이 더 높은 데 달려 있습니다.
무차별 대입 공격에 대한 가장 좋은 방어책은 해시 함수가 계산적으로 깨지기 어려울 만큼 긴 출력을 지원하는지 확인하는 것입니다. 해싱을 사용하여 비밀번호를 보호하는 경우 함수가 충돌하기 쉬운 경우 해시 출력 값의 길이를 늘리는 것만으로는 충분하지 않을 수 있습니다. 컴퓨터에 저장된 비밀번호 해시를 보호하려면 키 스트레칭 프로세스를 통해 엔트로피를 높일 수 있습니다.
'Fortinet > FCF - Technical Introduction' 카테고리의 다른 글
| Fortinet 자격증 FCF - 키와 암호화 알고리즘 (0) | 2024.09.05 |
|---|---|
| Fortinet 자격증 FCF - 암호화 및 PKI 모듈 Part 3 (0) | 2024.05.17 |
| Fortinet 자격증 FCF - 암호화 및 PKI 모듈 Part 2 (0) | 2024.05.16 |
| Fortinet 자격증 FCF - 암호화 및 PKI 모듈 Part 1 (0) | 2024.05.13 |