
I. 최단 경로 탐색의 개요
가. 최단 경로 탐색의 정의
그래프 내의 한 vertex에서 다른 vertex로 이동할 때 가중치의 합이 최솟값이 되는 경로를 탐색하는 알고리즘

Ⅱ. 최단 경로 탐색 알고리즘
가. 다익스트라 알고리즘 (Dijkstra Algorithm)
* 사이클이 없는 방향성에만 적용 * 가중치 합 최소 * Link State 알고리즘 활용
|
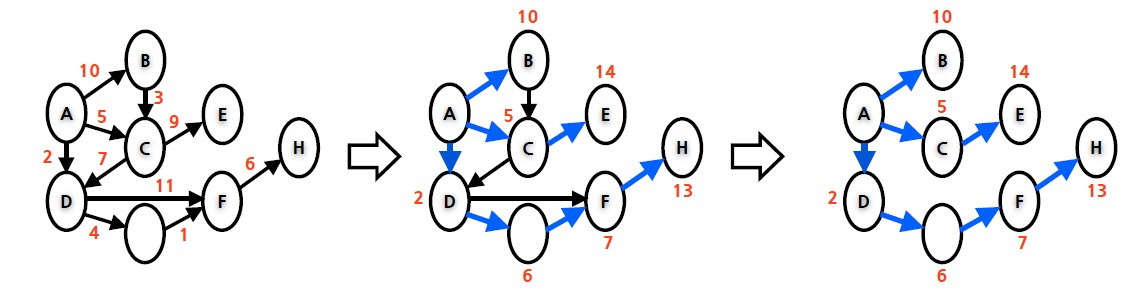 |
function Dijkstra(Graph, source): dist[source] := 0 // Distance from source to source for each vertex v in Graph: // Initializations if v ≠ source dist[v] := infinity // Unknown distance function from source to v previous[v] := undefined // Previous node in optimal path from source end if add v to Q // All nodes initially in Q end for while Q is not empty: // The main loop u := vertex in Q with min dist[u] // Source node in first case remove u from Q for each neighbor v of u: // where v has not yet been removed from Q. alt := dist[u] + length(u, v) if alt < dist[v]: // A shorter path to v has been found dist[v] := alt previous[v] := u end if end for end while return dist[], previous[] end function |
나. 벨만-포드 알고리즘(Bellman-Ford Algorithm)
* 사이클이 없는 방향성에만 적용 * 가중치의 음수 값도 고려 * Distance Vector 알고리즘 활용
|
 |
function BellmanFord(list vertices, list edges, vertex source) ::distance[],predecessor[] // Step 1: initialize graph for each vertex v in vertices: distance[v] := inf // At the beginning , all vertices have a weight of infinity predecessor[v] := null // And a null predecessor distance[source] := 0 // Except for the Source, where the Weight is zero // Step 2: relax edges repeatedly for i from 1 to size(vertices)-1: for each edge (u, v) with weight w in edges: if distance[u] + w < distance[v]: distance[v] := distance[u] + w predecessor[v] := u // Step 3: check for negative-weight cycles for each edge (u, v) with weight w in edges: if distance[u] + w < distance[v]: error "Graph contains a negative-weight cycle" return distance[], predecessor[] |
다. 플로이드 알고리즘
* 그래프에 존재하는 모든 정점 사이의 최단 경로를 한 번에 찾아주는 알고리즘 * 2차원 배열을 사용하여 3중 반복을 하는 루프로 구성 * 인접행렬 weight 구성
|
  |
shortest_floyd(int adj_matrix[][]){ dist[SIZE][SIZE]; dist[][] = adj_matrix[][]로 초기화 for(k=0; k < n; k++) for(i = 0; i < n; i++) for(j =0; j < n; j++) dist[i][j] = Min(dist[i][j], dist[i][k] + dist[k][j]); return(dist); } |
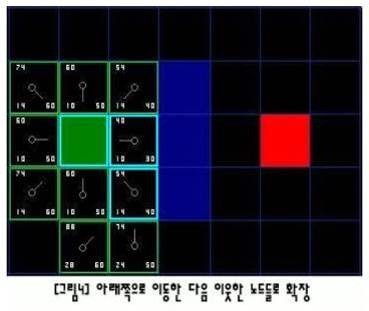
라. A* 알고리즘 (A* Algorithm)
* 시작지점에서 목표지점까지의 경로탐색을 위하여 휴리스틱 함수를 사용
|
||
|
||
 |
 |
 |
 |
 |
 |
'IT 용어 및 개념 > Algorithm' 카테고리의 다른 글
| [Algorithm] 힙 정렬 (Heap Sort) (0) | 2024.09.15 |
|---|---|
| [Algorithm] 백트래킹 알고리즘 (1) | 2024.09.15 |
| [Algorithm] 선택 정렬 (Selection Sort) (0) | 2024.09.15 |
| [Algorithm] 최소신장트리 알고리즘 (0) | 2024.09.15 |
| [Algorithm] 기수 정렬 (Radix Sort) (0) | 2024.09.14 |